Qualitative data can take many forms. Find a (non-exhaustive) list that showcases the possibilities of the types of materials that might fit into QDR at the bottom of this page. QDR has developed a simplified typology of types of data in the repository. You can use the facet at the bottom left of the repository to filter our holdings structured by this typology.
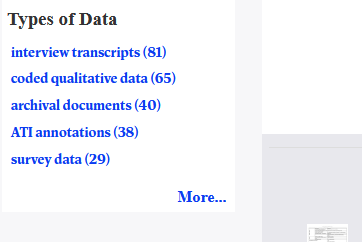
QDR's Data Typology
- archival documents
- ATI annotations
- audio recordings
- coded qualitative data
- field notes
- focus group transcripts
- interview transcripts
- maps
- narrative reports
- news sources
- pedagogical materials
- photographs
- quantitative data (non-survey)
- secondary sources
- social media/blog posts
- survey data
- transcript excerpts
- videos
- web sources (other)
Possibilities for Qualitative Data
- Data from structured, semi-structured, or unstructured interviews; focus groups; oral histories (audio/video recordings; transcripts; notes/summaries; questionnaires/interview protocols)
- Field notes (including from participant observation or ethnography)
- Maps/satellite imagery/geographic data
- Official/public documents, files, reports (diplomatic, public policy, propaganda, etc.)
- Meeting minutes
- Government statistics
- Correspondence, memoranda, communiqués, queries, complaints
- Parliamentary/legislative proceedings
- Testimony in public hearings
- Speeches, press conferences
- Military records
- Court records; legal documents (charts, wills, contracts)
- Chronicles, autobiographies, memoirs, travel logs, diaries
- Brochures, posters, flyers
- Press releases, newsletters, annual reports
- Records, papers, directories
- Internal memos, reports, meeting minutes
- Position/advocacy papers, mission statements
- Party platforms
- Personal documents (letters, personal diaries, correspondence, personal papers)
- Maps, diagrams, drawings
- Radio broadcasts (audio or transcripts)
- TV programs (video or transcripts)
- Print media (magazine, newspaper articles)
- Electronic media
- Published collections of documents, gazeteers, yearbooks, etc.
- Books, articles, dissertations, working papers
- Photographs
- Ephemera; popular culture visual or audio materials (printed cloth, art, music /songs, etc.)