DOI: https://doi.org/10.59350/5h25x-w2r21
Welcome to Love Data Week. Every year, research data professionals from libraries, data repositories, and other organizations celebrate great ways to use data and best practices in taking care of research data. You can find lots of us tweeting using #LoveData20 or #LoveDataWeek. At QDR, we’re celebrating this year by releasing our first software tool for researchers, the R package archivr (pronounced “archiver”).
The Problem
If you have done any research using web sources, you have probably run into this issue:
You used a web resource – a blogpost, a newspaper article, a statement from an organization – but when you want to come back to it, you can no longer find it. Even if you were smart enough to save the page at the time or you used a tool like Evernote or Zotero to take a Snapshot, citing the now gone webpage is of little help to other researchers who may want to follow up on your claims about it
A Solution
When this happens to you as a reader – e.g., when, you find a webpage cited that is no longer online, you may have used the WaybackMachine, an incredibly useful tool by the Internet Archive, a non-profit organization. The WaybackMachine allows you to look up a website and find an archived copy. Webpages associated with the Love Data Week event actually provide some great examples of this – the event used to be called “Love Your Data Week” but had to drop the name, and associated website, due to an existing trademark. While the live pages have disappeared, the Internet Archive allows us to find many archived copies of this site.

But this only works for sites that the Internet Archive has saved automatically. Sites that are only available for a short time and/or haven’t been linked to widely are often not archived in the Internet Archive. This is particularly true for non-English sources.
This is where archivr comes in. It allows you to automatically save all URLs in a spreadsheet or a Word file to the Internet Archive or perma.cc, a similar service run by a consortium of libraries led by the Harvard Law Library. So if you, for example, listed 100 URLs you consulted in an Excel sheet, you can make sure they’re archived. If you’ve written a chapter, or even an entire dissertation, archivr will find all URLs in the text and make sure they are archived.
By using archivr, you can be sure that scholars will always have access to the web pages you relied on.
At QDR, we have been using this tool for curation for several months now. We worked together with Agile Humanities’ Ryan Deschamps in building the original prototype and have since taken over maintenance of the tool.
An Example
In her masterful book Authoritarian Apprehensions, Lisa Wedeen draws, among other things, on 100s of web sources, many of them from Syria and thus particularly prone to disappearance. When curating data accompanying Lisa Wedeen’s book, QDR used archivr to make archived copies of all those sources, ensuring they’ll remain available. If readers of the book find a URL that is no longer working, they can simply search for it in the spreadsheet of archived URLs on QDR and find an archived copy instead
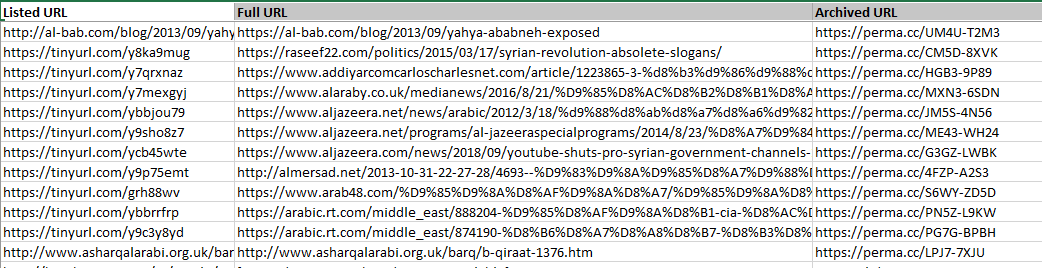
Using archivr
Archivr is easy to use, including for R-novices. Basic installation and usage instructions are included in the readme and detailed instructions and examples are in the built-in documentation.
If you are using archivr, please let us know what you think. If you have any feature requests or bug reports, email us at qdr@syr.edu or create an issue on the project’s github repository.